How to Build a Strong Data Quality Framework



 Verified
Verified
Investing in data quality transforms data management from a mere operational expense into a strategic asset. High-quality data enhances decision-making, streamlines processes, and facilitates swift regulatory compliance, leading to significant cost savings. Bringing in a high headcount to sift through bad data, regulatory fines due to late submissions, and increased product recalls are just a few examples of avoidable costs.
Businesses rely on data for decision-making, automation, and compliance, yet nearly 30% of their data is inaccurate, incomplete, or outdated. Poor data quality costs businesses an average of $12.9 million per year, leading to revenue losses, operational inefficiencies, and compliance risks. For instance, in the U.S. alone, poor data practices result in $3.1 trillion in annual losses.
The repercussions of substandard data extend to customer relations. Inaccurate information can lead to negative interactions and diminished trust, adversely affecting retention rates. Thus, ensuring robust data quality is not merely a current operational concern, but a strategic imperative.
Moreover, with the rise of artificial intelligence (AI) and machine learning, the need for high-quality data has intensified. High-quality data enables AI models to make accurate predictions and provide relevant recommendations, while flawed data can introduce biases and errors, undermining the reliability of AI outputs.
In this article, I will examine the financial and operational impact of poor data quality, its implications for AI and automation, and the strategies businesses must implement to ensure reliable, high-value data.
Understanding Data Quality
Data quality is a measure of how well data meets user requirements. Different users may have varying needs, so the implementation of data quality depends on their specific expectations. Identifying these needs is essential for ensuring data usability.
High-quality data does not mean it must be completely error-free. Instead, it should be fit for purpose. A “good enough” approach is often a practical starting point. Large organizations typically establish data governance policies that outline how data is managed, ensuring its quality and compliance with privacy regulations.
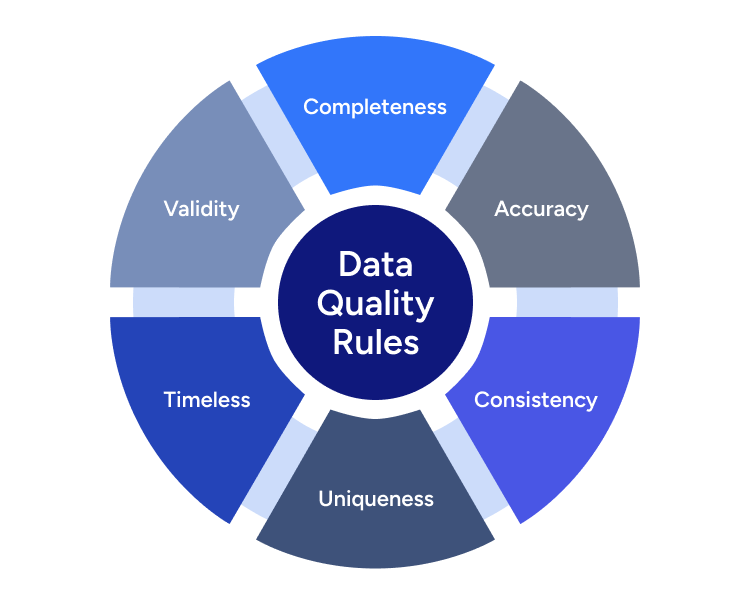
The Six Dimensions of Data Quality
Data quality covers multiple aspects, making it essential to define measurable criteria. It is typically assessed across six key dimensions:
- Accuracy: Data must correctly reflect the real-world object it represents. A record can follow all formatting rules but still be incorrect. Ensuring accuracy requires subject matter expertise to validate that the information makes sense in context.
- Completeness: Measures how much required data is present. Missing information—such as incomplete customer records or financial details—creates gaps in analysis and increases risk. Maintaining completeness supports better decision-making and operational efficiency.
- Consistency: Data should be identical across all sources and systems. Inconsistent records, such as variations in a customer’s name or conflicting product codes, lead to confusion and undermine trust in analytics. Standardized definitions and automated validation processes help prevent discrepancies.
- Uniqueness: Each entity should exist only once. Duplicate records distort reporting, inflate costs, and reduce efficiency. Implementing deduplication strategies prevents redundant entries and ensures a single, reliable version of each data point.
- Timeliness: Data must be available and up to date when needed. Delayed updates can result in missed opportunities or incorrect decisions, particularly in time-sensitive industries like finance and retail. Real-time or scheduled updates keep information relevant.
- Validity: Data must follow predefined formats and business rules. For example, email addresses should meet standard syntax, and birthdates should fall within reasonable limits. Enforcing validation rules prevents incorrect entries from entering the system.
Each dimension plays a role in maintaining data integrity, accuracy, and usability. Organizations that apply these principles consistently improve decision-making, reduce compliance risks, and enhance operational efficiency.
The Importance of Having a Data Quality Management Cycle
Like other quality management practices, data quality requires continuous monitoring and improvement. Organizations should implement a structured process that ensures consistent evaluation and enhancement of data quality.
This is why organizations need to create a cycle where data quality is not a one-time effort but an ongoing process. It helps organizations comply with regulatory requirements, prevent costly errors, and improve decision-making by providing accurate and reliable data.
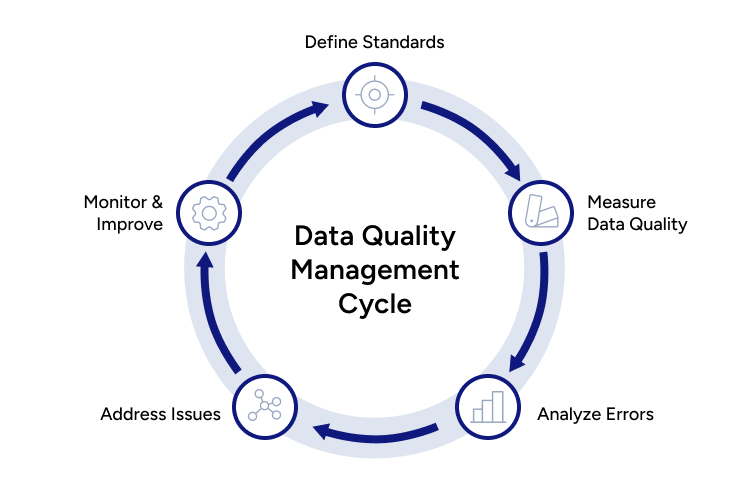
Define Standards
Organizations establish data quality standards based on business needs and regulatory requirements. These standards dictate acceptable levels of completeness, consistency, accuracy, uniqueness, integrity, and timeliness for data. The data owner and stewards work together to define these rules.
A key aspect of this phase is identifying critical data elements that need quality checks. Companies define quality rules based on industry regulations and internal business needs. Acceptable error thresholds are established to ensure that minor data inconsistencies do not disrupt operations.
Measure Data Quality
After defining the standards, data quality checks are implemented to measure data against these predefined rules. Automated validation processes run within the data warehouse to detect anomalies at different stages of data processing.
This phase involves running automated validation checks, identifying missing or inconsistent data, and logging detected issues. These measurements ensure that data discrepancies are flagged for review before they impact business operations.
Analyze Errors
Once data quality issues are detected, the next step is analyzing errors to determine their impact on business processes. Data users and data owners assess the severity of identified issues and decide on corrective actions.
The analysis focuses on identifying the root cause of errors, prioritizing issues based on business impact, and deciding whether immediate correction is necessary or if issues can be handled in the next data cycle. Understanding patterns in errors helps organizations prevent recurring problems.
Address Issues
After analyzing errors, corrective actions are taken to fix the identified issues. The approach varies depending on the severity of the problem. Some errors may require reprocessing data, while others may involve modifying transformation logic or addressing discrepancies at the source system level.
Fixing errors may involve implementing adjustments in data transformation rules, updating data at the source, or communicating necessary changes to data providers. Ensuring that these issues are properly addressed prevents them from reoccurring in future data loads.
Monitor and Improve
The final phase involves continuous monitoring of data quality to maintain acceptable standards. Organizations track data quality trends over time, refine validation rules, and introduce new checks when necessary.
Monitoring involves tracking recurring data quality issues, updating data validation rules, and evaluating the effectiveness of past corrections. If certain rules become obsolete, they should be revised or removed. Long-term trend analysis helps detect systemic data quality issues that need broader process improvements.
By consistently following this Data Quality Management Cycle, organizations proactively manage data quality issues, ensure compliance with regulatory standards, and enhance decision-making through accurate and reliable data.
Why Having a Data Governance Framework is Key
A robust data governance framework is essential for maintaining data integrity. Though there is no “right way” to organize Data Governance, this framework should typically include a Data Governance Council responsible for high-level decisions, ensuring consistent data management across the organization. Implementing a structured data management hierarchy ensures accountability and effective collaboration. A typical structure includes:
Chief Data Officer (CDO)
The CDO is responsible for defining and overseeing the organization’s data strategy. This includes governance policies, regulatory compliance, and the alignment of data initiatives with business objectives. The CDO ensures that data is treated as a strategic asset, enforcing enterprise-wide data management practices and fostering a culture of data-driven decision-making.
Data Governance Council
This cross-functional team makes high-level decisions regarding data policies, compliance requirements, and governance structures. The council ensures that data governance standards are consistently applied across departments, aligning data policies with business needs and regulatory frameworks. It also provides oversight for data quality initiatives and resolves conflicts related to data ownership and usage.
Data Owners
A data owner is accountable for the overall quality, privacy, and security of a specific data domain (e.g., customer data, financial records, or marketing insights). Data owners control who has access to data, define usage policies, and ensure compliance with governance rules. In large organizations, multiple data owners oversee different domains, but one senior stakeholder should be responsible for the overall data quality framework. Strong authority, business expertise, and decision-making skills are essential for this role.
Data Stewards
Data stewards work under data owners and are responsible for implementing data quality measures within their assigned domain. Their role includes monitoring data consistency, enforcing governance policies, and assisting users in understanding data models. They bridge the gap between IT and business teams by ensuring that data aligns with operational needs while adhering to technical and regulatory standards. Successful data stewards require a mix of analytical skills, business knowledge, and strong communication abilities to coordinate across departments.
Data Engineers and Analysts
These professionals handle the technical aspects of data integration, cleansing, and transformation to maintain data quality at scale. They build pipelines that process, validate, and store data from multiple sources while applying rules to detect and correct errors. Data analysts interpret data for business insights, ensuring that datasets remain accurate, timely, and relevant for decision-making.
Project-Level Data Managers
In large-scale projects, data quality must be maintained at every stage, from initial design to final implementation. Project-level data managers ensure that data governance policies are applied consistently across specific initiatives. Their responsibilities include defining data quality expectations, ensuring data integrity during migrations, and coordinating with business teams to align data with project objectives.
In project structures, data management is embedded at every stage, from design to migration to go-live. Cross-functional collaboration ensures that all teams have access to reliable, high-quality data, enabling efficiency and innovation.

Building a Strong Foundation for Data Quality
To establish effective data quality, organizations must first ensure that all teams use the same definitions for key attributes. Inconsistent terminology leads to misaligned reporting and operational inefficiencies. A centralized data dictionary helps maintain uniform definitions, allowing teams to reference and update attributes as needed. Any changes must be reviewed and approved by relevant stakeholders to ensure consistency across departments.
Beyond definitions, clear system ownership and process alignment are essential. Each data attribute must have a single accountable owner responsible for its accuracy in the master data repository. Another role may handle data entry, but accountability remains with the designated steward. Aligning processes across regions or legacy systems is complex and often requires change management expertise to ensure clarity in who manages data, how it flows, and who can modify it.
A strong data culture starts with leadership. Without executive support, data management initiatives often fail. Organizations should start small, focus on a single use case, and demonstrate tangible benefits before scaling. Successful data governance requires a full support team—not just data specialists but also business leaders who drive adoption, ensure compliance, and align teams toward a unified data strategy.
Case Study: Setting up Data Quality Department
In a recent project with Consultport, I was involved in setting up the data quality department and the data quality framework within a newly formed data management team. We have completed a first phase, and are ramping up to start our second phase. Some of the key learning from our phase 1 is that we should start small, with one specific use-case and make that use-case as small as possible in terms of data attributes. Once the benefits are clear, scaling becomes much easier with broader buy-in.
We’ve also reemphasized the importance of looking at the full end-to-end process. Understanding where data originates and where business requests come from helps align expectations and ensures a complete, effective solution. Losing this perspective often leads to mismatched outcomes.
Finally, we’ve seen time and time again that data management isn’t just about technology—it requires strong processes, change management, and ownership. Success only comes when leadership actively champions a comprehensive support system.

How Freelance Data Scientists Can Help
The demand for independent data experts is rising as businesses are adopting AI, machine learning, and data-driven strategies. Companies with strong data capabilities are 23 times more likely to acquire customers and 19 times more likely to be profitable, making data science expertise a competitive advantage.
The global data science market, valued at $95 billion in 2024, is projected to grow at a CAGR of 27.7% through 2030, reflecting the increasing reliance on predictive analytics, automation, and big data solutions. At the same time, the number of independent consultants grew by 69% between 2020 and 2022, with over 90% of corporate leaders expressing interest in leveraging freelance talent for specialized projects.
Freelance data scientists in Consultport’s network bring expertise in data quality governance, data management, and advanced analytics, helping businesses establish a robust data quality framework. They ensure that data remains accurate, consistent, and reliable, enabling companies to enhance AI-driven insights, automate data validation, and comply with regulatory standards.
Want to build a stronger data governance strategy? Find a consultant now.
 Verified
VerifiedJef brings in-depth expertise in Operational Excellence, Master Data Management, ERP implementations, and Supply Chain optimization. With experience in automotive, biopharma, and industrial automation, he helps companies streamline data governance, enhance operational efficiency, and implement large-scale ERP systems. He has led projects in master data integration, process optimization, and cost efficiency for global enterprises.
on a weekly basis.
